多列复合索引的使用 绕过微软sql server的一个缺陷
导读:1建站知识多列复合索引是指由多个字段组成的索引。这种情况相当常用的,并且,在查询中,用多列复合索引来指定搜索范围网站建设制作企业网站建设。
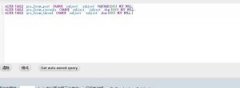
 然而,微软sql server在处理这类索引时,有个重要的缺陷,那就是把本该编译成索引seek的操作编成了索引扫描,这可能导致严重性能下降 举个例子来说明问题,假设某个表T有索引 ( cityid, sentdate, userid), 现在有个分页列表功能,要获得大于某个多列复合索引V0的若干个记录的查询,用最简单表意的方式写出来就是 V >= V0, 如果分解开来,就是: cityid > @cityid0 or (cityid = @cityid0 and (sentdate > @sentdate0 or (sentdate = @sentdate0 and userid >= @userid0))), 当你写出上述查询时,你会期待sql server会自动的把上述识别为V >= V0类型的边界条件,并使用index seek操作来实施该查询。然而,微软的sql server (2005版)有一个重要缺陷(其他的sql server如何还不得知), 当它遇到这样sql时,sql server就会采用index scan来实施,结果是您建立好的索引根本就没有被使用,如果这个表的数据量很大,那所造成的性能下降是非常大的。 对于这个问题,我曾经提交给微软的有关人士,他们进一步要求我去一个正式的网站上去提交这个缺陷,我懒得去做。 不过,对这个缺陷,还是有个办法能够绕过去的,只要把上面给出的条件变变形,sql server还是能够变回到是用index seek, 而不是低性能的index scan. 具体请看我的英文原文吧(对不起了, 我一旦写了中文,就不想翻成英文,反过来也一样, 估计大家英文都还可以,实在不行的就看黑体部分吧, ): The seek predicate of the form "x > bookmark_of_x" is needed in paging related query. The compiler has no difficulty to parse it correctly if x is a single column index, or two columns index, however, if x is a three columns index or more, then the compiler will have a hard time to recognize it. This failure will result in that the seek predicate ended up in residue predicate, which results in a much worse execution plan. To illustrate the point, take a example, Create table A( a int, b int, c int, d float, primary key (a, b, c)) now check the plan for the query: select c, d from A where (a> 111 or a= 111 and (b > 222 or b = 222 and c > 333)) you can see a table scan op is used, and the Where clause ended up in residue predicate. However, if you rewrite the query in an equivalent form: select c, d from A where a> 111 or a= 111 and b > 222 or a= 111 and b= 222 and c >333 Then the compiler can choose an index seek op, which is desired. The problem is, the compiler s网站优化seo培训hould be able to recognize the first form of seek predicate on multiple columns index, it saves the user from having to pay extra time to figure out a get-around, not to mention the first form is a more efficient form of same expression. 上面的问题,可以说是部分的绕过去了,但是,也有绕不过的时候,接着看下面一段: It looks like that sql server lacks a consept of vector bookmark, or vector comparison or whatever you like to call it. The workaround is not a perfect workaround. If sql server were to understand the concept of vector bookmark, then the following two would be the same in execution plan and performance: 1. select top(n) * from A where vectorIndex >= @vectorIndex 2. select * from A where vectorIndex >= @vectorIndex and vectorIndex <=@vectorIndexEnd -- @vectorIndexEnd corresponds to the last row of 1. However, test has shown that, the second statement takes far more time than the first statement, and sql server actually only seek to the begining of the vector range and scan to the end of the whole Index, instead of stop at the end of the vector range. Not only sql server compile badly when the vector bookmark has 3 columns, test has shown that even with as few as 2 columns, sql serer still can not correctly recognize this is actually a vector range, example: 3. sele个业网站建设公司ct top (100) a, b, c, d from A where a> 60 or a= 60 and b > 20 4. select a, b, c, d from A where (a> 60 or a= 60 and b > 20) and (a< 60 or a= 60 and b <= 21), 上面两个查询实质相同(表中的数据刚好如此),并且给出同业的结果集,但是,3比4的速度要快的多,如果去看execution plan也证明3确实应当比4快. 也就是说, 即使在索引vectorIndex只含两列的情况下, sql server也无法正确的理解范围表达式 @vectorIndex0 < vectorIndex < @vectorIndex1, 它能把前半部分正确的解读为seek, 但是, 后半部分无法正确解读, 导致, sql server会一直扫描到整个表的末尾, 而不是在@vectorIndex1处停下来. 以下测试代码, 有兴趣的人可以拿去自己玩:
然而,微软sql server在处理这类索引时,有个重要的缺陷,那就是把本该编译成索引seek的操作编成了索引扫描,这可能导致严重性能下降 举个例子来说明问题,假设某个表T有索引 ( cityid, sentdate, userid), 现在有个分页列表功能,要获得大于某个多列复合索引V0的若干个记录的查询,用最简单表意的方式写出来就是 V >= V0, 如果分解开来,就是: cityid > @cityid0 or (cityid = @cityid0 and (sentdate > @sentdate0 or (sentdate = @sentdate0 and userid >= @userid0))), 当你写出上述查询时,你会期待sql server会自动的把上述识别为V >= V0类型的边界条件,并使用index seek操作来实施该查询。然而,微软的sql server (2005版)有一个重要缺陷(其他的sql server如何还不得知), 当它遇到这样sql时,sql server就会采用index scan来实施,结果是您建立好的索引根本就没有被使用,如果这个表的数据量很大,那所造成的性能下降是非常大的。 对于这个问题,我曾经提交给微软的有关人士,他们进一步要求我去一个正式的网站上去提交这个缺陷,我懒得去做。 不过,对这个缺陷,还是有个办法能够绕过去的,只要把上面给出的条件变变形,sql server还是能够变回到是用index seek, 而不是低性能的index scan. 具体请看我的英文原文吧(对不起了, 我一旦写了中文,就不想翻成英文,反过来也一样, 估计大家英文都还可以,实在不行的就看黑体部分吧, ): The seek predicate of the form "x > bookmark_of_x" is needed in paging related query. The compiler has no difficulty to parse it correctly if x is a single column index, or two columns index, however, if x is a three columns index or more, then the compiler will have a hard time to recognize it. This failure will result in that the seek predicate ended up in residue predicate, which results in a much worse execution plan. To illustrate the point, take a example, Create table A( a int, b int, c int, d float, primary key (a, b, c)) now check the plan for the query: select c, d from A where (a> 111 or a= 111 and (b > 222 or b = 222 and c > 333)) you can see a table scan op is used, and the Where clause ended up in residue predicate. However, if you rewrite the query in an equivalent form: select c, d from A where a> 111 or a= 111 and b > 222 or a= 111 and b= 222 and c >333 Then the compiler can choose an index seek op, which is desired. The problem is, the compiler s网站优化seo培训hould be able to recognize the first form of seek predicate on multiple columns index, it saves the user from having to pay extra time to figure out a get-around, not to mention the first form is a more efficient form of same expression. 上面的问题,可以说是部分的绕过去了,但是,也有绕不过的时候,接着看下面一段: It looks like that sql server lacks a consept of vector bookmark, or vector comparison or whatever you like to call it. The workaround is not a perfect workaround. If sql server were to understand the concept of vector bookmark, then the following two would be the same in execution plan and performance: 1. select top(n) * from A where vectorIndex >= @vectorIndex 2. select * from A where vectorIndex >= @vectorIndex and vectorIndex <=@vectorIndexEnd -- @vectorIndexEnd corresponds to the last row of 1. However, test has shown that, the second statement takes far more time than the first statement, and sql server actually only seek to the begining of the vector range and scan to the end of the whole Index, instead of stop at the end of the vector range. Not only sql server compile badly when the vector bookmark has 3 columns, test has shown that even with as few as 2 columns, sql serer still can not correctly recognize this is actually a vector range, example: 3. sele个业网站建设公司ct top (100) a, b, c, d from A where a> 60 or a= 60 and b > 20 4. select a, b, c, d from A where (a> 60 or a= 60 and b > 20) and (a< 60 or a= 60 and b <= 21), 上面两个查询实质相同(表中的数据刚好如此),并且给出同业的结果集,但是,3比4的速度要快的多,如果去看execution plan也证明3确实应当比4快. 也就是说, 即使在索引vectorIndex只含两列的情况下, sql server也无法正确的理解范围表达式 @vectorIndex0 < vectorIndex < @vectorIndex1, 它能把前半部分正确的解读为seek, 但是, 后半部分无法正确解读, 导致, sql server会一直扫描到整个表的末尾, 而不是在@vectorIndex1处停下来. 以下测试代码, 有兴趣的人可以拿去自己玩:
声明: 本文由我的SEOUC技术文章主页发布于:2023-05-24 ,文章多列复合索引的使用 绕过微软sql server的一个缺陷主要讲述微软,缺陷,微软网站建设源码以及服务器配置搭建相关技术文章。转载请保留链接: https://www.seouc.com/article/web_6528.html