浅谈SQL Server中统计对于查询的影响分析建站知识
导读:1建站知识SQL Server查询分析器是基于开销的。通常来讲,查询分析器会根据谓词来确定该如何选择高效的查询路线,比如该选择哪高端网站建设建设网站公司。
 而每次查询分析器寻找路径时,并不会每一次都去统计索引中包含的行数,值的范围等,而是根据一定条件创建和更新这些信息后保存到数据库中,这也就是所谓的统计信息。 如何查看统计信息 查看SQL Server的统计信息非常简单,使用如下指令: DBCC SHOW_STATISTICS('表名','索引名')所得到的结果如图1所示。
而每次查询分析器寻找路径时,并不会每一次都去统计索引中包含的行数,值的范围等,而是根据一定条件创建和更新这些信息后保存到数据库中,这也就是所谓的统计信息。 如何查看统计信息 查看SQL Server的统计信息非常简单,使用如下指令: DBCC SHOW_STATISTICS('表名','索引名')所得到的结果如图1所示。
统计信息如何影响查询
下面我们通过一个简单的例子来看统计信息是如何影响查询分析器。我建立一个测试表,有两个INT值的列,其中id为自增,ref上建立非聚集索引,插入100条数据,从1到100,再插入9900条等于100的数据。图1中的统计信息就是示例数据的统计信息。
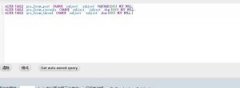
此时,我where后使用ref值作为查询条件,但是给定不同的值,我们可以看出根据统计信息,查询分析器做出了不同的选择,如图2所示。
where id= 12345 where monthly_sales < 10000 / 12 where name like “Careyson” + “%”
但是对于比如
where price = @vari where total_sales > (select sum(qty) from sales) where a.id =b.ref_id
where col1 =1 and col2=2
这类在运行时才能知道值的查询,采样步长就明显不是那么好用了。另外,上面第四行如果谓词是两个查询条件,使用采样步长也并不好用。因为无论索引有多少列,采样步长仅仅存储索引的第一列。当柱状图不再好用时,SQL Server使用密度来确定最佳的查询路线。
密度的公式是:1/表中唯一值的 个建设网站数。当密度越小时,索引越容易被选中。比如图1中的第二个表,我们可以通过如下公式来计算一下密度:
根据公式可以推断,当表中营销型网站建设的数据量逐渐增大时,密度会越来越网站seo优化培训小。
对于那些不能根据采样步长做出选择的查询,查询分析器使用密度来估计行数,这个公式为:估计的行数=表中的行数*密度
那么,根据这个公式,如果我做查询时,估计的行数就会为如图4所示的数字。
我们来验证一下这个结论,如图5所示。
因此,可以看出,估计的行数是和实际的行数有出入的,当数据分布均匀时,或者数据量大时,这个误差将会变的非常小。
统计信息的更新由上面的例子可以看到,查询分析器由于依赖于统计信息进行查询,那么过时的统计信息则可能导致低效率的查询。统计信息既可以由SQL Server来进行管理,也可以手动进行更新,也可以由SQL Server管理更新时手动更新。
声明: 本文由我的SEOUC技术文章主页发布于:2023-05-23 ,文章浅谈SQL Server中统计对于查询的影响分析建站知识主要讲述浅谈,标签,SQL网站建设源码以及服务器配置搭建相关技术文章。转载请保留链接: https://www.seouc.com/article/web_5552.html